앞서 우리는 머신러닝이 무엇인지에 대해 알아봤습니다.
이중 지도학습 방법에서 사용되는 회귀모델에 대해 이야기 해보겠습니다.
회귀(Regression)는 주어진 입력변수(독립)와 추력변수(종속, 예측하려는 값) 사이의 관계를 모델링하는 방법입니다.
보통 독립변수와 종속변수 사이의 수학적 함수로 표현됩니다.
선형회귀(Linear Regression)는 독립 변수들과 종속 변수 간의 관계를 예측할 때, 즉 x와 y의 관계를 예측할 때, 그 사이 관계를 선형관계라고 가정을 하고 모델링하는 방법입니다. 보통 인자와 결과 간의 대략적인 관계 해석이나 예측에 활용됩니다.
y = wx + b 형태로 독립변수가 1개일 경우, 단순선형회귀,
y = w_1x_1 + w_2x_2 + ... + w_nx_n + b 형태로 독립변수가 2개 이상이면 다중선형회귀로 부릅니다.
이때 독립변수 x는 Feature, 즉 특성이 됩니다.
선형회귀모델은 최소제곱법(OLS, Ordinary Least Squares)을 사용해 학습합니다. 최소제곱법은 모델이 예측한 값과 실제 값의 차이, 즉 잔차(Residual)의 제곱을 최소화 하는 방법입니다.

y_i는 독립 변수 x_i에 대한 실제 값, y_i hat은 x_i에 대해 모델이 예측한 값입니다. 모델이 예측한 값이 실제 값과 차이가 없을 수록 잘한 예측이 되겠죠. 이 차이를 줄이는 것이 선형회귀모델의 목적이 됩니다.
최소제곱법을 사용하는 이유는
- 부호 문제 제거
- 잔차는 양값과 음값이 모두 존재하여, 그냥 더하면 서로 상쇄됩니다. 그래서 제곱을 해 오차의 크기만을 남깁니다. - 오차 민감도 증가
- 작은 오차는 제곱하여도 큰 영향이 없지만 큰 오차는 더 쉽게 발견할 수 있습니다.
등의 이유가 있습니다.
OLS는 앞서 말한 선형회귀 모델 y=wx+b에서 가중치인 w와 편향 b를 찾는 방법입니다. 그럼 앞서 찾은 회귀계수를 평가는 어떻게 하는걸까요
- MSE(Mean Squared Error)
- 큰 오차를 강하게 강조하고 싶을 때 사용합니다. 제곱의 구조 때문에 이상치가 있으면 값이 급격히 튑니다.
미분이 가능하다. - RMSE(Root Mean Squared Error)
- 오차 크기를 원래 스케일로 보고 싶을 때 사용합니다. MSE는 제곱 단위이기때문에 제곱근으로 y와 동일 단위로 만들어줍니다.
미분이 불가능하다 - MAE(Mean Absolute Error)
- 데이터 세트의 잔차 평균을 측정한 것으로, MSE, RMSE에 비해 오차값이 이상치의 영향을 상대적으로 크게 받지 않아서 이상치에 대해 둔감한 편입니다.
미분이 불가능하다 - 결정계수 R2
- 결정계수 R2는 TSS(Total Sum of Squares), RSS(Residual Sum of Squares)를 이용한 것 인데,
이때 TSS는 모든 y_i의 평균값과 y_i의 차이를 제곱하여 더한 값으로, 어떠한 모델도 적용되지 않았을 때의 상황이라고 볼 수 있습니다.
RSS는 잔차제곱합으로 회귀 모델을 사용했을 때 잔차의 제곱합입니다.
결정계수 R2는 1에 RSS를 TSS로 나눈 값(1 - RSS/TSS)을 빼서 나오는 값으로, 1에 가까울수록 일반적으로 예측력이 좋다고 해석합니다.
Adj R2 는 독립변수 개수가 증가할수록 결정계수가 같이 커지는 경향을 보정하기 위해 나타낸 지표입니다.

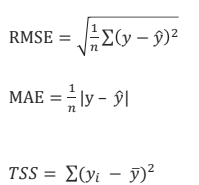
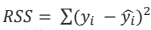

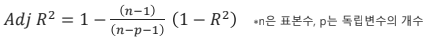
앞서 회귀모델은 최적의 모델이 되는 w와 b를 찾는 것이 목적이라고 했습니다. 그럼 어떻게 찾는걸까요.
대표적으로 많이 언급되는 것이 경사하강법(Gradient Descent) 입니다.
다음 포스팅에서 경사하강법에 대해 다뤄보겠습니다.
'Machine Learning' 카테고리의 다른 글
| [Machine Learning] Bias-Variance Tradeoff (0) | 2026.02.20 |
|---|---|
| [Machine Learning] Logistic Regression (0) | 2026.02.20 |
| [Machine Learning] Gradient Descent (0) | 2026.02.20 |
| [Machine Learning] Machine Learning? (0) | 2026.02.05 |



