회귀모델은 연속적인 값(집값예측과 같은)을 예측하는데 사용되곤 합니다.
하지만 어떤 종양이 암인지 아닌지를 예측해야되는 상황도 우리 주변에 있습니다.
이때 사용되는것이 로지스틱 회귀입니다.
로지스틱 회귀는 데이터가 어떤 범주(category)에 속할 확률을 0에서 1사이의 값으로 예측하는 모델입니다.
확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류 해주는 것이죠
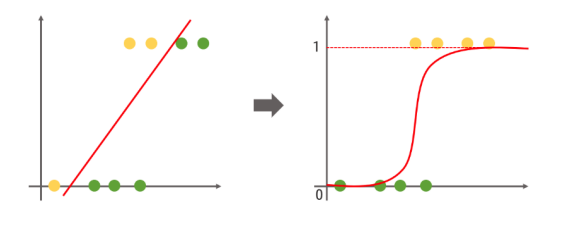
선형회귀의 출력값은 -∞ ~ +∞ 사이에 있지만
분류 문제의 출력은 0 또는 1입니다.
분류 문제에서는 값이 아니라 맞거나 틀릴 확률을 예측해야합니다.
LogOdds
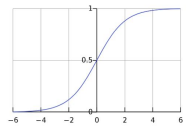
Odds 는 사건이 발생할 확률을 발생하지 않을 확률로 나눈 것입니다.
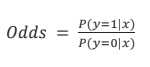
LogOdds는 Odds에 Log를 취한 값입니다.

우리가 구하는 값은 사건이 발생할 확률로, 위 식을 P(y =1 | x) 에 대해 정리하면

다음과 같은 식이 나오게 되는데 이를 Sigmoid 함수라고 합니다.
시그모이드 함수는 출력값을 0과 1사이로 압축해 보여주는데,
우리는 0과 1 사이의 확률을 예측해야하기 때문에 사용하게 됩니다.
MLE (Maximum Likelihood Estimation) 최대 가능도 추정
MLE는 정답일 확률을 최대화 하는 것이 목표입니다.
위의 시그모이드 함수에서 손실(예측이 틀릴 확률)을 최소화 하는
가중치 w를 찾는 것이 핵심입니다.
반대로 가능도(정답일 확률)을 최대화 하는 w를 찾을 수도 있겠죠.
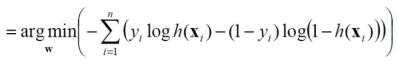
위 식은 로그손실 함수에서 로그값에 음수를 취해
w가 최대가 되는 값을 찾는 식에서
w가 최소가 되는 값을 찾는 식으로 변경한 것입니다.
선형회귀와 같이 경사하강법을 사용해 w를 찾을 수 있습니다.
다중 분류의 경우 이중 분류와는 달리 3개 이상의 클래스 중 하나를 예측해야합니다.
타겟이 가지는 값에 대응되는 데이터 집합을 클래스 또는 레이블이라고 하는데,
다중 분류는 단일 레이블 분류로, 입력 값 하나당 하나의 클래스에만 대응합니다.
이진 분류와 달리 여러 개의 출력 값을 가지고, 각 출력값은 타겟과 매칭 될 확률을 의미합니다.
Sigmoid함수를 일반화한 Softmax함수는 결과값을 확률 처럼 해석합니다. 가장 높은 값에 대응되는 클래스가 모델의 예측값이 됩니다.

다중 분류의 손실함수는 다음과 같습니다.
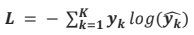
K는 클래스의 개수, y는 One-hot label, y_hat은 Softmax출력 확률을 의미합니다.
'Machine Learning' 카테고리의 다른 글
| [Machine Learning] Bias-Variance Tradeoff (0) | 2026.02.20 |
|---|---|
| [Machine Learning] Gradient Descent (0) | 2026.02.20 |
| [Machine Learning] Regression (0) | 2026.02.05 |
| [Machine Learning] Machine Learning? (0) | 2026.02.05 |



